Situation:
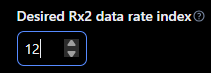
Im running into a recurring sporadic problem where Class C devices stop receiving downlinks. I believe I’ve narrowed the issue to the Network Server scheduling the downlink using a different data rate than what’s set. Currently, I have the desired rx2 data rate set to 12, and ADR is turned off on both the Network Server and the end device.
When I first start the device, it is able to receive downlinks, but after a certain amount of time (say 24-48 hours) the Network Server changes the data rate. I am able to verify that the data rate changes by looking at the debugging logs of my gateway. See an example below where dr=13 instead of 12
Not only the datarate is different, also the frequency is. The default Rx2 frequency for US915 (which I assume you’re using, you haven’t mentioned that) is 923.3MHz. However, your log shows 926.9MHz, which is a normal downlink channel.
When using Class C, the usual Rx1 and Rx2 window are still valid. Rx2 admittedly is equal to the RxC (class C) window, but to me, it appears very likely that these downlinks are simply scheduled as normal downlinks.
Is there a problem with those downlinks being sent in the Rx1 window instead of the Rx2/RxC window? Did you specifically set these to Class C downlinks, or did you simply schedule “a downlink”?
(Note that I don’t know if they are actually sent in Rx1, it’s my best guess. It could very well be something else at play here.)
Correct this is US915. I realised in my excitement to send the logging data I had attached a log for a confirmed uplink reply, so I assume thats why the frequency is different.
Now murphys law is at play and I cannot even get the NS to schedule a confirmed downlink for the effected end device, though unconfirmed downlinks are being scheduled.
I’ll update the logs when I figure out how to get the downlinks working correctly, though my original issue still stands…stay tuned
Both are pushing the boundaries of mainstream usage and may be contributing to the problem. Confirmed uplinks could push the downlink to Rx2 or even just the gateway not having the air time. SF12 needs a smallish packet to stay under dwell time limits - and the LA requests network providers to limit the use of SF11 & 12.
Do you devices really need SF12 or is this just “to be sure”?
If I am manually initiating a downlink I don’t really need a high DR. For me my main concern with downlinks is reliability.
To clarify, I am not talking about downlinks being sent as a result of a confirmed uplink. I am referring to downlinks I am sending to update device states for my application. I can try lowering the RX2 DR to see if that resolves the problem.
It seems the behavior has changed since my first debugging attempts. So currently, some devices I still cannot send confirmed downlinks, but now they are not even being scheduled. If I look at my gateway logs both in the TTS interface (in verbose mode), and logging over serial, there are no logs for the downlink.
Here is the image of the end device logs when I send a confirmed downlink
A Class C downlink is scheduled using the best gateway, usually in terms of RSSI as long as dutycycle allows (at least, that it how it should be, correct me if I’m wrong @johan).
If the device is received by another gateway with a stronger signal, the downlink will be scheduled through that gateway, which may not be the one that you are looking at. Recently, a proper gateway was installed by someone else relatively close to my house which has been messing with my assumptions, too - sometimes that one turns out to be the one sending JoinAccepts or downlinks.
Class C downlinks will not be scheduled until the device has sent an uplink in its session. If the device rejoined but did not send an uplink, there will not be a Class C downlink until after the uplink (because it has to figure out which gateway is best to use). I doubt this is the case for you, but just for completeness.
Why are you repeatedly mentioning “confirmed downlinks”? Is it really only for confirmed downlinks? Or also for unconfirmed ones? I just checked on my own device that hasn’t sent an uplink in 7 days: both unconfirmed and confirmed Class C are happily transmitted by the ‘best’ gateway.
Confirmed downlinks are very bad for the network and can quickly end up with a device being stuck in a loop if it doesn’t handle them well - either the content causes issue or it doesn’t generate the confirmation.
I would strongly recommend not sending confirmed downlinks ever. Confirmed uplinks aren’t much better. Forum search provides a huge body of knowledge on confirmations.
This rang a bell - the spec says that “there may be only a single confirmed Class C downlink pending an acknowledgement”. It is very likely that somewhere in the chain, the downlink is not confirmed. The spec mandates a solution: the device has to respond to a Class C confirmed downlink within a certain time period. But that likely didn’t happen for one or more of multiple reasons…
Recommended solution is to not use confirmed downlinks indeed.
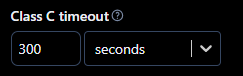
Right, this is the Class C timeout. By default, this is quite short, 10 seconds or so.
For Class C to be enabled, the session must be confirmed by the end-device via a first data uplink message after receiving the join-accept. So 1) join-request, 2) join-accept, 3) data uplink message, then the NS checks whether Class C is supported, and it will start the downlink task to send application downlink via class C.
Indeed, the gateway selection is at the discretion of the NS, based on downlink path constraints, SNR, RSSI, duty-cycle and scheduling conflicts. So if there are multiple gateways covering the end-device, it is not immediately clear which one will transmit downlink (regardless of Class A, B or C).
1 & 2. This is possible and I wont rule it out, however I know that my end devices are not receiving these downlinks as I have debugged by connecting to them over serial and reading their logs. I’m also less certain this is the case because there is very little coverage in my area and I’ve setup all my devices on FSB 8 (to clarify this is a paid version of The Things Stack Cloud, not TTN)
3. Yes I notice this is the case when the device first powers on, however this issue starts to occur 1-2 days after reboot, with regular uplinks
4. I mention confirmed downlinks as I can see these are not being scheduled. I can see unconfirmed downlinks being scheduled (both on TTS and my gateway logs). This also makes me think this isnt another gateway in the area, because if unconfirmed downlinks are being scheduled on my gateway, then I would also expect confirmed downlinks to be scheduled.
To clarify I am running a paid version of TTS Cloud, not TTN. While I can see that some features of the TTS may have limitations, I would expect that using a paid version of the service I should be able to access all features, provided I’m complying with local regulations on duty cycle, etc. If the LoRaWAN protocol has provisions for confirmed downlinks, then I don’t think its too unreasonable to use that. If they truly are that bad then they should remove them from the protocol standard (though this is getting beyond the scope of my problem )
With regards to an infinite loop, I believe TTS has an 8 attempt timeout for confirmed downlinks
@stevencellist Just so I understand, are you proposing that at some point, the server sent a confirmed downlink to an end device, and for one reason or another never received an acknowledgement. So now it refuses to schedule any more confirmed downlinks because its still pending this acknowledgement? Is this not what the Class C timeout parameter is for? My problem is that once a device falls into this state, it never recovers from it.
I had a look for your quote, and see this falls under the 1.0.4 lorawan specification, though my devices are setup at 1.0.3, so unsure if that line would apply to them anyway.
@johan When I first boot the devices, I will test that they are able to receive confirmed downlinks by manually initiating them after first uplink. I can see both on my gateway and end device that these confirmed downlinks are being scheduled. But then this problem arises after 1-2 days. Like I previously mentioned I’m not entirely convinced this is an issue of another gateway in the area, for the reasons stated.
Is there more detailed logging I can see using the tts cli? I currently have no way of knowing what is happening after sending a confirmed downlink as the verbose output doesnt say much on the web interface.
This is totally irrelevant - no mention was made of the FUP - I was referencing the impact on the airwaves - the local Wide Area Network - and, for confirmed uplinks, the consequences for the gateway & lost uplinks from other devices.
As I suggested, forum search will uncover many discussions on the perils of confirmations. Being in the spec doesn’t make any one piece of functionality applicable just because there is the option to use it. They do have a time & place but reliance on them for comms on a shared radio spectrum can lead to unintended consequences.
When sending multiple downlinks in relatively quick succession, the confirmed downlinks do go missing (not showing on gateway console). However, after leaving the device alone for in my case 14 minutes, it did actually transmit the confirmed downlink I scheduled.
My guess would be that if one schedules a confirmed downlink, the LNS checks whether the timeout period has occurred since the previous downlink, even if that was not a confirmed one.